
The AI pilot's over
Infosys Consulting
WORK
Lauren Kelly
The AI pilot’s over
SNAPSHOT
Infosys Consulting came to us at a point lots of organisations recognise.
The AI tools were already out in the wild. People had been trained. The intent was there. And yet, day to day, usage still felt uneven. Confident in one moment, hesitant in the next. Strong in one team, patchy in another. Not because anyone was doing something “wrong”, but because new tools tend to meet old habits, real risk, and busy work.
That’s when adoption stops being a training topic and starts being a behaviour topic.
So we spent seven weeks getting close to what was actually happening across teams: where AI use held up, where it wobbled, and what made the difference. From that, we built a simple system teams can run without outside help, combining quick diagnosis with practical moves that fit into existing meetings and workflows.
If you want the research, the patterns we found, and what we built, read on.
Infosys Consulting
AI Adoption Build

Infosys Consulting came to us with a familiar situation that still catches organisations off guard.
The AI tools had been rolled out. Training had happened. The decks said adoption was underway.
But on the ground, usage was... mixed.
In one meeting, a manager would be all in while the team stayed quiet. Two people on the same project would use the same tool in completely different ways. Someone would use AI confidently for research, then refuse to touch it when the work became client-facing.
It wasn’t a yes-or-no adoption problem. It was a consistency problem. And consistency is what turns “we have AI” into “we work differently now”.




Infosys had tried training. It helped individuals, but it didn’t create consistency. So they asked us to look at it differently: as a behaviour problem, not a capability problem. How do we move from scattered AI use to confident, aligned, everyday performance?
We ran a seven-week sprint with ten leads across design, research, and change to understand what was actually driving the variance, not what the rollout plan assumed.
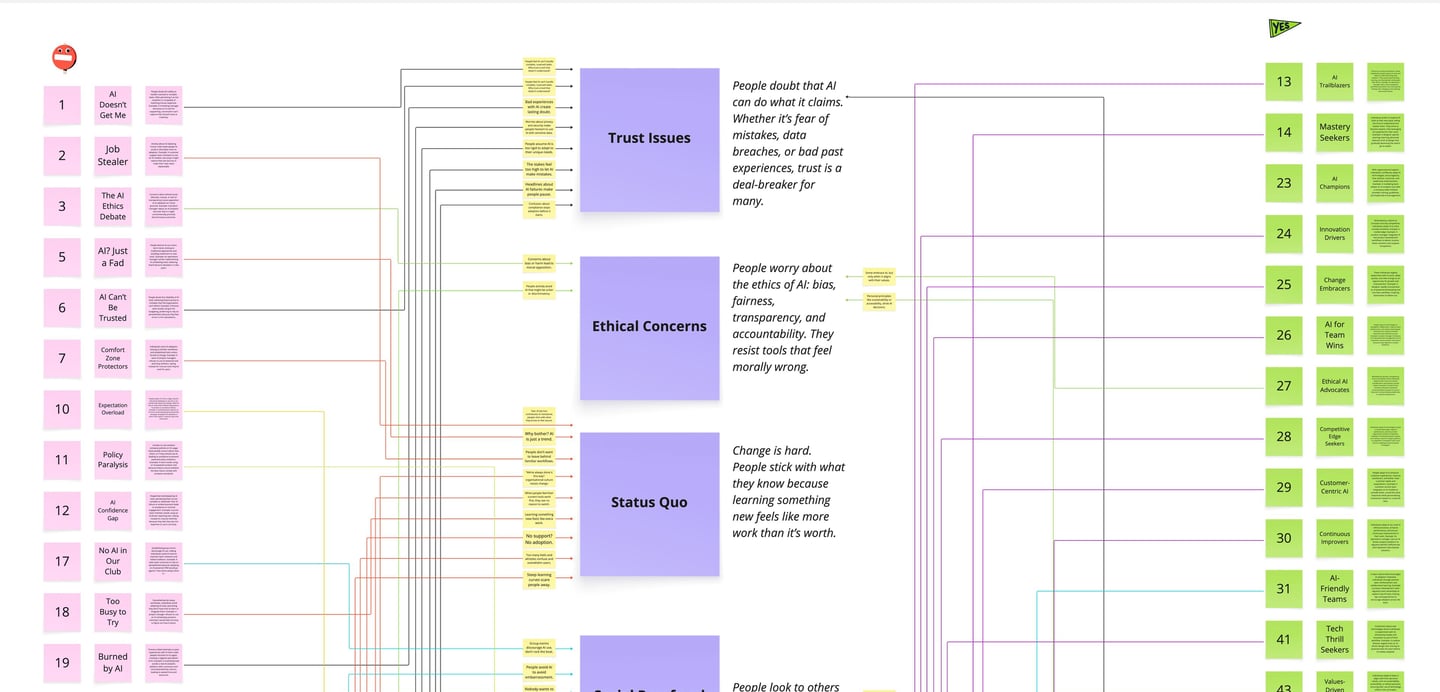

The inconsistency wasn’t random. It had patterns.
We interviewed leaders inside Infosys and ran parallel research across finance, health, telecoms, and government. Three findings kept surfacing.
Trust was fragile and binary.
75% of people took AI outputs as-is until something visibly broke. Then confidence collapsed and often didn’t recover. On the same team you’d see over-reliers and avoiders, shaped by different experiences.
AI was changing team dynamics.
45% said conversation shrank when AI-generated options entered the room. People deferred to the output instead of thinking together. Collaboration flattened, but only in certain contexts, which made it hard to diagnose.
Nobody knew who owned AI-informed decisions.
68% of leaders saw shared AI as a game-changer, but couldn’t say who was accountable when something went wrong. Without clear ownership, some people over-relied and others avoided.
Training couldn’t fix this. You can’t train your way to trust, shared norms, or clear ownership. You have to design for them.






What we built
The interview work gave us a lot of truth, but not a clean starting point. We ended up with fifty-plus friction points. Useful detail, but as a list it didn’t help teams decide what to do next.
So we grouped the frictions into five levers that kept showing up underneath the variance: Trust, Enable, Fit, Capability, Adapt. That gave Infosys a shared way to talk about what was actually blocking consistent use, without turning it into opinions or personality.
From there, the system needed two things: fast diagnosis, and practical moves.
The diagnostic does the first job. It’s fifteen questions, takes about ten minutes, and tells you which lever is stuck. Teams stop guessing and start where it matters.
The methods handle the blockers that kept repeating in different forms. Role boundaries, ownership, governance, and change over time. The AI / Me / We Canvas makes responsibilities in a workflow visible. Ownership Radar assigns a clear human owner to AI-informed outputs. Policy Translation turns governance into guidance people can use in the moment. Context Checkpoint is a simple routine for updating norms when tools, risks, or teams shift.
Then we put the system into a format that works in real conversations. Cards.
Pattern cards describe what teams can actually see happening, and what it tends to cost. Profile cards help facilitators recognise different mindsets in the room, so the response isn’t one-size-fits-all. Playbook cards give step-by-step interventions that fit into existing meetings.
Everything was built so a team can run it without external support.










“Genuinely blew us away.
Full of ‘why didn’t we think of that?’ moments.”
Katie Milioni
CEO, MyHabeats
Go deeper with our Human AI Performance series:
View more work
© 2026, BehaviourStudio All rights reserved. Behaviour Thinking is a registered trademark of BehaviourStudio.