
A system in seven years
From card decks to a contradiction-resolution engine. What changed, and what the system now knows it doesn't know.
BUILDING BEHAVIOURKIT
Lauren Kelly
3/27/2026
BehaviourKit started as card decks on a workshop table. Today it's a typed ontology with a contradiction matrix, evidence traceability, protective controls, confidence levels, transparency outputs, and a translation layer that exists in design if not yet in full content.
If you'd asked me in 2018 what I was building, I would have said: tools that help practitioners use behavioural science. That answer was true and it was incomplete. What I was actually building, though I couldn't see it at the time, was a knowledge engine that encodes expert reasoning about behaviour change into a system that can work without the expert present.
Every phase of the project has been a step toward making more of that reasoning explicit.


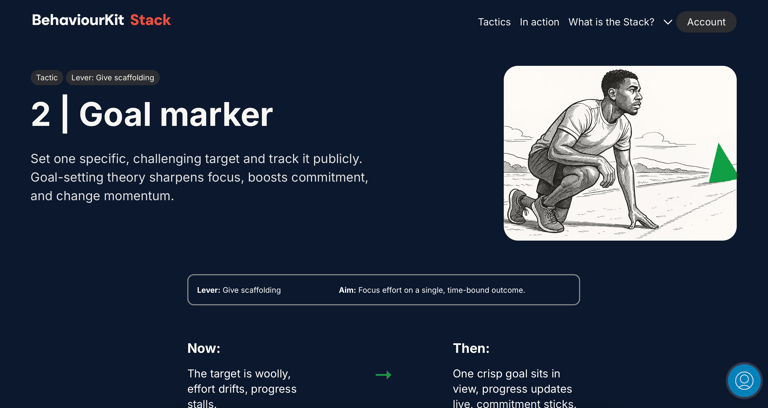
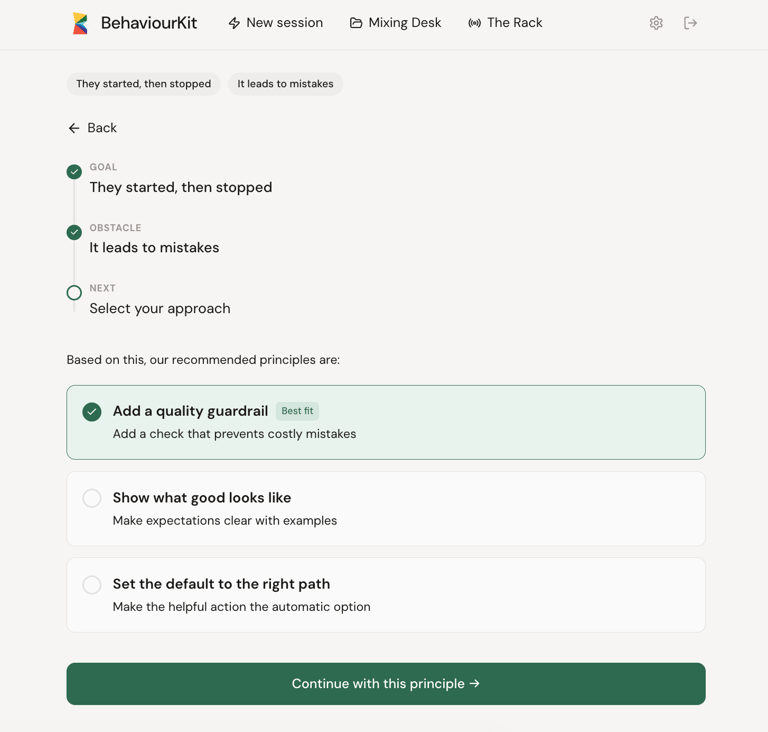
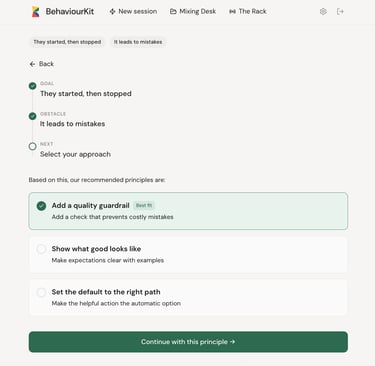
The patterns made the intervention knowledge explicit. Instead of relying on individual practitioners to know what's been tried and what's worked, the system holds fifty-two named, evidence-grounded intervention patterns. The Drive Grid made the diagnostic knowledge explicit. Instead of relying on intuition to identify what's driving a behaviour, the system provides a structured set of questions across nine driver types. The contradiction matrix made the routing knowledge explicit. Instead of relying on expert judgement to connect a diagnosis to a recommendation, the system maps sixty-three specific contradictions to specific principles and plays. The ontology repair made the construct quality explicit. Instead of relying on labels that sounded right, the system now classifies each construct by type, assesses its state model honestly, and tracks the confidence level of every route.
The most important thing the system gained in the past year is honesty about what it doesn't know.
Every recommendation now carries a confidence basis. Direct mechanism match, plausible but broad, conditional match, or weak. Every route has a status: primary, secondary, conditional, or "no clear primary." Every suppressed option has a reason code. Every protective control has a trigger and a rationale.
The system can say: "I'm recommending this, and here's why. My confidence is moderate because the driver you've described could be interpreted in two ways. Here's a question that might help us be more precise."
That sentence would have been unthinkable in the card-deck era. A card deck doesn't express uncertainty. It presents options and leaves the judgement to you. An engine that expresses uncertainty, that says "here's my best answer and here's how much I trust it," is a fundamentally different kind of tool. It respects the user enough to be transparent about the limits of its own reasoning.
I think that's better. It's harder to market, admittedly. "We'll give you a recommendation and also tell you when we're not sure" is less punchy than "change behaviour fast." But it's more trustworthy. And in a field where bad recommendations can cause real harm, where the wrong intervention in the wrong context can make a behaviour problem worse rather than better, trustworthiness matters more than confidence.
Here's what I still need to build.
The translation layer needs populating. The system knows it needs a registry that maps everyday user language to diagnosis constructs with confidence levels. The design exists. The content doesn't. That's a large, careful content generation task: hundreds of terms, each mapped to constructs, each with disambiguation logic for ambiguous expressions.
The tactic layer needs the same rigorous audit that the driver and lever layers received. It's been reviewed but not repaired to the same standard. The tactic-to-play mappings need honest quality ratings.
The full diagnostic flow, the deeper version of Quick Start that handles complex or multi-driver problems, needs UX specification. The architecture supports it. The user experience hasn't been designed yet.
Maintenance mode needs building. Quick Start helps someone take a safe first action. But what happens when that action starts to wobble? When the behaviour fades, gets patchy, or loses quality? The system needs a way to help people adjust, not just start. That's the retention story for the product, and it's the part that acknowledges what practitioners have always known: most behaviour change fails in the middle, not at the start.
Seven years. Four hundred academic papers. Fifty-two patterns. Twenty-five drivers. Twelve principles. Sixty-three matrix cells. Ninety plays. Three protective control types. Four construct types. Honest state models. Confidence levels. And a growing awareness that the more precisely you understand a problem, the more clearly you see what you haven't solved yet.
The system is the most honest it's ever been. Which means it's also the most aware of its own gaps. I think that's the right direction. The card decks didn't know what they didn't know. The engine does.
That's progress. The uncomfortable, productive kind.
Go deeper into the Building BehaviourKit series:
© 2026, BehaviourStudio All rights reserved. Behaviour Thinking is a registered trademark of BehaviourStudio.